
I know I said this was a 4-part series, but who doesn’t love bonus content? This edition is all about User-Defined Functions (UDFs).
Check out the previous editions of the series using the links below:
UDFs (User-Defined Functions) are a way to create bespoke functions in SQL.
For example, if I wanted to find the cube of a number, I could do the following in a query:
--bigquery syntax\nSELECT power(<COLUMN>,3) as cubed\nFROM <TABLE>
But if I wanted to create a function to cube any number that I could use instead of POWER, I could create one called cubed:
--bigquery syntax\nCREATE OR REPLACE FUNCTION\n<DATASET>.cubed(x FLOAT64)\nRETURNS FLOAT64 AS ( POWER(x,3) );
Then whenever I want to cube something, I could call our new function:
SELECT\n<DATASET>.cubed(3), \n<DATASET>.cubed(2.2)\n\n-- 27.0 , 10.648000000000003
And importantly, now anyone with query access to my database can use this new function too.
The implementation of UDFs will differ in every database you’re using (fun!), so be sure to check your own DB documentation before using them. But there are a few things they all have in common:

The functionality of UDFs gives us a glimpse of how close SQL is to being a “proper” coding language.

One of the most popular features of Python or R is the ability to modularize code for re-use through the use of functions. Platforms like pypi, tidyverse, and npm have taken this even further by letting users share these functions beyond their teams and to the entire community of users.
Today most SQL is written as isolated scripts, but UDFs facilitate sharing logic between scripts, emulating the module systems of other ‘real’ programming languages.
More importantly, UDFs give us a framework to make SQL work better for us and those around us. We can use UDFs to:
Let’s say the Sales team often looks at data quarterly but struggles to get data in the right format. To assist, I could make a function that turns any date (2020–01–02) into a quarter (Q1–2020) so they aren’t fighting with pedantic date formatting functions and can carry on doing their analysis.
Since you can use other languages to create UDFs you have the ability to inject SQL with the functionality it doesn’t otherwise have. For example, you can use JavaScript NLP libraries to create a function that finds the Levenshtein distance (link) between two words, letting you more easily do fuzzing joining on text columns, something notoriously difficult in SQL.
But there is a reason we aren’t all living in a UDF utopia. As great as UDFs can be, their drawbacks often leave us wondering if they’re worth the trouble at all.
In particular:
UDFs usually require admin privileges to create and maintain, meaning only certain users will be able to see how they’re defined. But these same functions can be available for any user to use, meaning many will be blindly using a function they can’t see.
Their bespoke nature also means there is no help for anyone struggling with one of these functions. My sales team can’t use Google to see why they’re getting errors on the quarter function I created since I’m the only one who knows how it works.
Furthermore, if I built a UDF using something other than SQL (e.g. JavaScript), I really can’t share it with many people. If it suddenly stops working and I’m not around, I’m not confident my data team can fix it. As a wise Uncle once said, “With great power comes great responsibility.”
Combined, these two drawbacks threaten one of the fundamental reasons we use SQL: it’s a low-level querying language. This means while it is verbose, it is fairly standardized. I don’t have to worry about people using odd libraries with unknown functions and methods; everyone is using the same standard SQL functions and syntaxes.
This, then, is our trade-off. How do we use UDFs to help us and those around us work better with SQL without undermining its strength as a universally understood language?
Given this tradeoff, I like to use UDFs for two things only:
⚠️ I advise against using UDFs for anything resembling business logic (e.g. a function that calculates revenue a certain way). For things like that it’s best to be able to show users what you’ve done and explain why, as it underpins the understanding of results.
Median
Source: bigquery-utils
BigQuery (and others) don’t have a native function for MEDIAN, instead of leaning on PERCENTILE_CONT window functions. This is fine, but I find it (1) annoying, and (2) difficult to explain to an introductory user as it requires understanding window functions.
This snippet, written for BigQuery calculates the MEDIAN of a column:
CREATE OR REPLACE FUNCTION <DATASET>.median(arr ANY TYPE) AS (( SELECT IF (\n MOD(ARRAY_LENGTH(arr), 2) = 0, (arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2) - 1)] + arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]) / 2, arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]\n )\n FROM\n (SELECT ARRAY_AGG(x ORDER BY x) AS arr FROM UNNEST(arr) AS x)\n ));
Weekday
Source: SQL Snippets
This definitely falls under the “simple but annoying things to do in SQL” category. Some dialects have ways to get the actual day of the week name, but in many cases, I’m left doing this lovely case statement again and again. So now it can be a function called weekday.
CREATE OR REPLACE FUNCTION <DATASET>.weekday(dt DATE) RETURNS STRING AS (\n case when extract(DAYOFWEEK from dt) = 1 then 'Sunday'\n when extract(DAYOFWEEK from dt) = 2 then 'Monday'\n when extract(DAYOFWEEK from dt) = 3 then 'Tuesday'\n when extract(DAYOFWEEK from dt) = 4 then 'Wednesday'\n when extract(DAYOFWEEK from dt) = 5 then 'Thursday'\n when extract(DAYOFWEEK from dt) = 6 then 'Friday'\n when extract(DAYOFWEEK from dt) = 7 then 'Saturday'\n end\n );\n
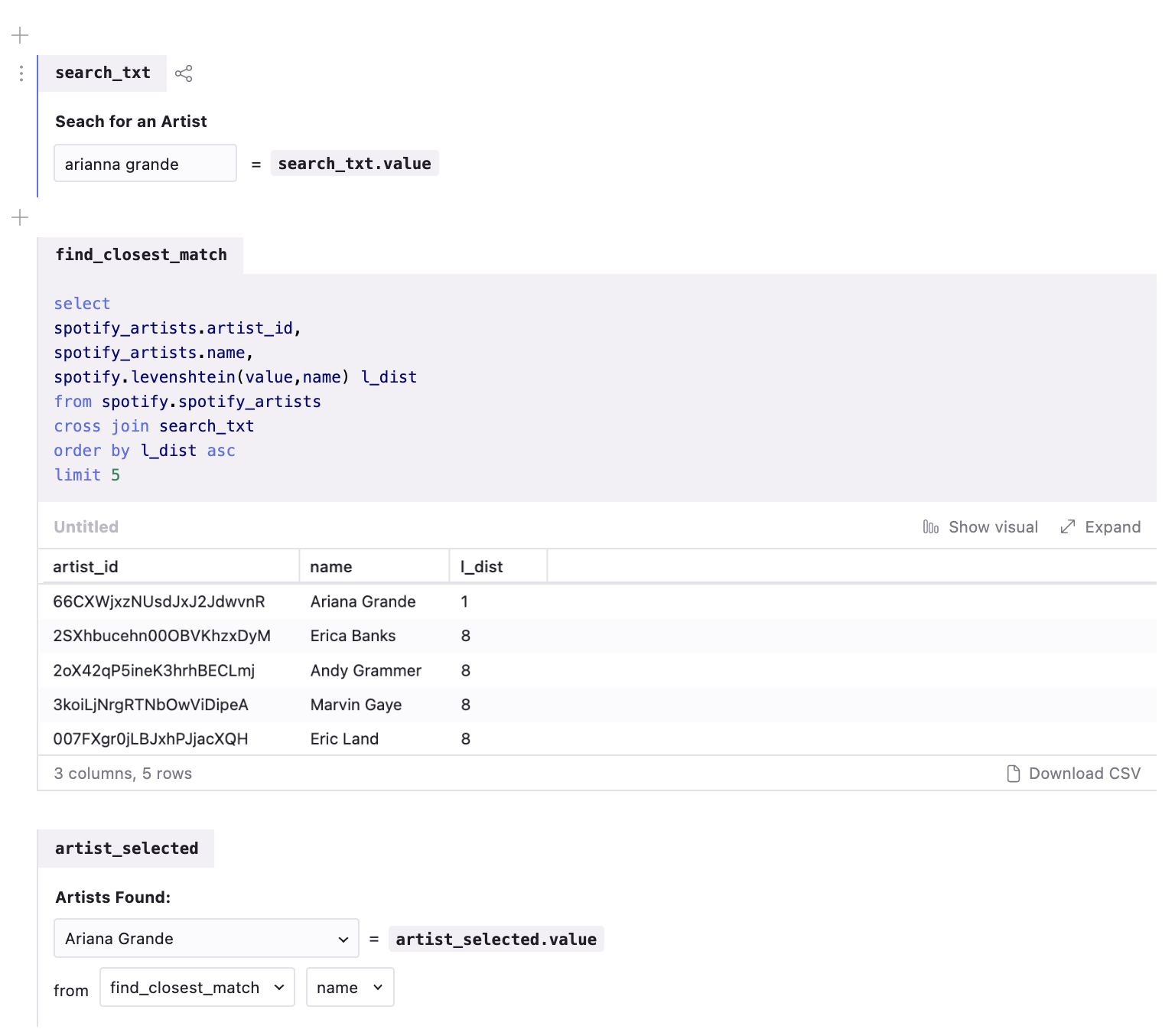
Levenshtein distance
Source: Felipe Hoffa
Levenshtein distance measures the ‘distance’ between two strings by the changes that would be required to change one to the other, so it can be a helpful way to find words that would otherwise match except for misspellings or other slight differences.
This is technically possible to do in SQL without using a JavaScript library (see proof here), but this is so much easier…
Recently, I’ve been wondering what role UDFs will play in SQL’s evolution. Our desire to be able to easily re-use SQL is growing ever more rapacious and is now one of the most frequent requests I hear from analysts.

It’s not hard to imagine UDFs being a part of the solution that propels SQL out of this local maxima and into a new era— one where we SQL users can collectively build powerful modules of code that can be distributed and enjoyed by all.
To try to spur this along, we started this SQL Snippets Collection. Here, SQL users can start to work towards an open-source solution by creating, sharing, and improving UDFs outside of your company’s database and into the larger community.



